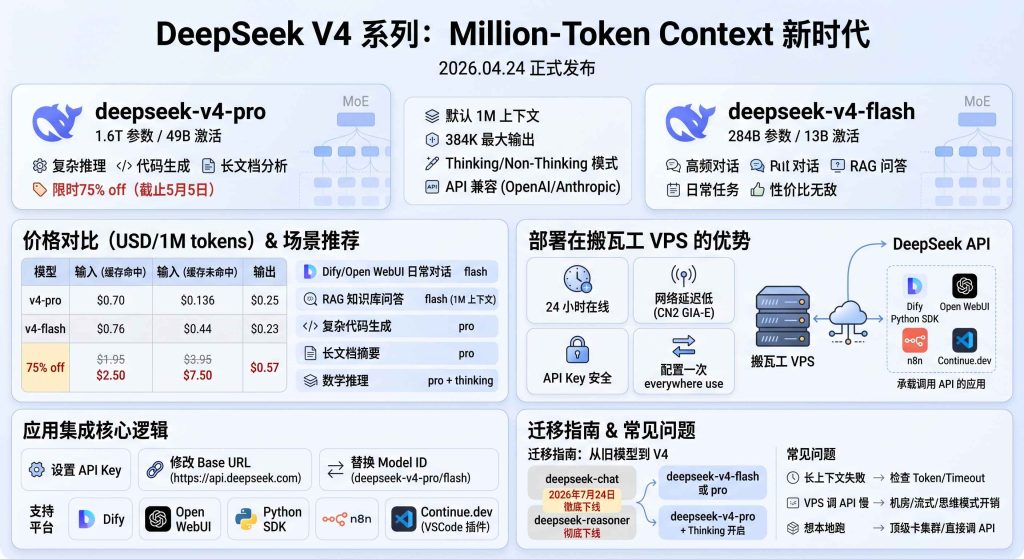
DeepSeek 在 2026 年 4 月 24 日正式发布了 V4 系列,分 deepseek-v4-pro(1.6T 参数 / 49B 激活)和 deepseek-v4-flash(284B / 13B 激活)两个版本,默认 1M token 上下文 + 384K 最大输出,且兼容 OpenAI 和 Anthropic API 格式。这意味着你在搬瓦工 VPS 上跑的任何应用,比如 Dify、Open WebUI、LangChain、自研脚本等,只要原本支持 OpenAI 接口,把 base_url 一改、model 一换就能用上 V4。
搬瓦工 VPS 上原来跑 deepseek-chat 的 Dify、Open WebUI 的模型可以全部切到 V4-Pro,体感推理能力明显上来一截,价格反而下降。这篇教程把完整接入流程写出来,包括 curl 直调、Python OpenAI SDK、Node.js、Dify/Open WebUI 集成、Thinking mode 控制、缓存优化,一篇覆盖。
⚠️ 重要提醒:旧的 deepseek-chat 和 deepseek-reasoner 模型将在 2026 年 7 月 24 日 15:59 UTC 彻底下线,到时只能用 V4 系列。建议现在就开始迁移。
相关文章:
一、DeepSeek V4 概况
V4 是 DeepSeek 第一个从头围绕百万级上下文设计的开源模型家族,发布即开源(MIT 协议),权重在 Hugging Face 上免费下载。
| 模型 | 总参数 | 激活参数 | 上下文 | 最大输出 | 适用场景 |
|---|---|---|---|---|---|
| deepseek-v4-pro | 1.6T | 49B | 1M tokens | 384K tokens | 复杂推理、长文档分析、高质量代码生成 |
| deepseek-v4-flash | 284B | 13B | 1M tokens | 384K tokens | 高频对话、日常任务、成本敏感场景 |
两个模型都基于 MoE(专家混合)架构,激活参数远小于总参数,所以推理成本可控。
关键特性
- 默认 1M 上下文:不需要任何特殊参数,输入再长也能直接吃下
- 双模式:每个模型都支持 Thinking(推理模式,类似 R1)和 Non-Thinking(直答模式),通过
thinking参数切换 - OpenAI / Anthropic API 双兼容:base_url 不用改,只改 model 字段
- MIT 开源:权重可以下载到自己服务器跑(但 1.6T 的 Pro 版需要顶级显卡集群,普通 VPS 跑不动)
Pro 还是 Flash:怎么选
直接看价格和场景:
1、价格对比(USD / 1M tokens)
| 模型 | 输入(缓存命中) | 输入(缓存未命中) | 输出 |
|---|---|---|---|
| deepseek-v4-flash | $0.028 | $0.14 | $0.28 |
| deepseek-v4-pro(限时 75% off) | $0.03625 | $0.435 | $0.87 |
| deepseek-v4-pro(原价) | $0.145 | $1.74 | $3.48 |
⚠️ V4-Pro 的 75% 折扣截止 2026 年 5 月 5 日 UTC 15:59,之后恢复原价。这段时间疯狂用 Pro 是最划算的。
2、场景推荐
| 场景 | 推荐模型 | 理由 |
|---|---|---|
| Dify / Open WebUI 日常对话 | flash | 速度快、成本低,足够好用 |
| RAG 知识库问答 | flash | 1M 上下文足够塞下大量文档 |
| 复杂代码生成 / 重构 | pro | Pro 在 agentic coding 上明显胜出 |
| 长文档摘要(500K+ tokens) | pro | 长文本理解能力 Pro 更强 |
| 数学推理 / 算法题 | pro + thinking 模式 | 开 thinking 后接近 o1 水平 |
| 高频客服机器人 | flash | 成本敏感,flash 性价比无敌 |
站长的建议:默认用 flash,遇到复杂任务再切 pro。配合 Dify 的”模型路由”功能可以自动按问题难度分配。
二、为什么部署在搬瓦工 VPS 上
DeepSeek V4 的真实推理在 DeepSeek 服务器上完成,搬瓦工 VPS 主要是承载调用 V4 API 的应用——Dify、Open WebUI、LangChain Agent、自研 Bot 等。把这些应用部署在搬瓦工上的好处:
1、24 小时在线
API 调用方应用需要持续运行(比如 Telegram Bot、定时任务、Webhook 接收器)。本地电脑合上盖就停,VPS 不存在这个问题。
2、网络延迟低
DeepSeek API 主服务在国内,搬瓦工的 CN2 GIA-E 线路对国内服务的访问速度比海外网络好得多。从搬瓦工调 DeepSeek API,单次请求往返通常 100-200ms,体验流畅。
3、API Key 不暴露
把 API Key 放在 VPS 的环境变量里,前端只调用 VPS 上的接口,Key 永远不会出现在浏览器或客户端代码里,安全性比”本地 + 前端直调”高得多。
4、配置一次到处用
VPS 上配好 V4 接入后,Dify、Open WebUI、n8n 等所有应用共用一套配置,改 Key 改 base_url 都只改一处。
关于搬瓦工套餐和线路的选择,参考和。
如果还没买搬瓦工 VPS,看文末套餐推荐。SSH 登录基础操作不熟练的话,先看。
三、获取 DeepSeek API Key
1、注册 DeepSeek 账号
打开 https://platform.deepseek.com,用邮箱或者手机号注册账号。
2、充值
DeepSeek 按用量付费,需要预先充值。最低充值额度通常是 $1 起,配合 V4-Pro 的 75% 折扣,$5 能用很久。
3、创建 API Key
登录后进入”API Keys”页面,点”Create new API key”:
- 给 Key 起个名字,比如
bandwagonhost-vps-1 - 创建后会显示完整 Key,只显示一次,立刻复制保存
- Key 格式:
sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
⚠️ 安全提示:API Key 绝对不要写死在代码里,更不要提交到 GitHub。下面所有示例都用环境变量传递。
四、curl 直接调用
最简单的验证方式,看看你的 API Key 是否有效。
1、设置环境变量
SSH 登录搬瓦工 VPS 后:
export DEEPSEEK_API_KEY="sk-你的key"
要永久生效,写入 ~/.bashrc:
echo 'export DEEPSEEK_API_KEY="sk-你的key"' >> ~/.bashrc
source ~/.bashrc
2、调用 deepseek-v4-flash
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-d '{
"model": "deepseek-v4-flash",
"messages": [
{"role": "system", "content": "你是一个简洁的助手"},
{"role": "user", "content": "用一句话介绍搬瓦工"}
],
"stream": false
}'
正常会返回类似:
{
"id": "...",
"model": "deepseek-v4-flash",
"choices": [{
"message": {
"role": "assistant",
"content": "搬瓦工是一家美国老牌 VPS 服务商..."
},
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 25,
"completion_tokens": 30,
"total_tokens": 55
}
}
3、调用 deepseek-v4-pro(开启 thinking 模式)
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-d '{
"model": "deepseek-v4-pro",
"messages": [
{"role": "user", "content": "证明:根号 2 是无理数"}
],
"thinking": {"type": "enabled"},
"stream": false
}'
开启 thinking 后,返回结果会包含 reasoning_content 字段(推理过程)和 content 字段(最终答案)。
五、Python(OpenAI SDK)调用
DeepSeek API 完全兼容 OpenAI SDK,不用装 DeepSeek 专属库。
1、安装 OpenAI SDK
sudo apt update
sudo apt install -y python3 python3-pip python3-venv
# 创建虚拟环境(推荐)
python3 -m venv ~/deepseek-venv
source ~/deepseek-venv/bin/activate
# 安装 OpenAI SDK
pip install openai
2、基础调用脚本
创建 chat.py:
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com",
)
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "system", "content": "你是一个简洁的助手"},
{"role": "user", "content": "搬瓦工 VPS 适合做什么"},
],
stream=False,
)
print(response.choices[0].message.content)
print(f"Tokens used: {response.usage.total_tokens}")
运行:
python chat.py
3、流式输出
实时打印 AI 的回复(像 ChatGPT 网页那样逐字出):
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com",
)
stream = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": "写一篇 200 字的搬瓦工 VPS 介绍"},
],
stream=True,
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
print()
4、长上下文调用(1M tokens)
V4 默认 1M 上下文,扔进去整本书都没问题:
with open("long_document.txt", "r") as f:
long_text = f.read()
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "请基于以下文档回答问题"},
{"role": "user", "content": f"文档内容:\n{long_text}\n\n问题:请总结要点"},
],
)
print(response.choices[0].message.content)
百万 token 大约对应 70-80 万字中文,普通技术文档堆几十份都能塞下。
六、Thinking 模式控制
V4 的双模式是它最有意思的设计——同一个模型,开关 thinking 切换”快答”和”深思”。
1、参数说明
{
"thinking": {"type": "enabled"} // 开启推理模式
}
或者:
{
"thinking": {"type": "disabled"} // 关闭(默认)
}
2、读取推理过程
开 thinking 后,响应里会多一个 reasoning_content 字段(推理过程),content 仍然是最终答案:
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[{"role": "user", "content": "999 * 999 = ?"}],
extra_body={"thinking": {"type": "enabled"}},
)
print("推理过程:")
print(response.choices[0].message.reasoning_content)
print("\n最终答案:")
print(response.choices[0].message.content)
⚠️ Thinking 模式会消耗更多输出 token(推理过程也算 output),所以成本会上升。简单任务别乱开。
七、集成到 Dify / Open WebUI
把搬瓦工 VPS 上跑的现成 AI 平台接入 V4。
1、Dify 接入 V4
打开 Dify 后台 → “设置” → “模型供应商” → 找到 DeepSeek 或 OpenAI-API-compatible:
| 字段 | 填写 |
|---|---|
| API Key | 你的 sk-xxx |
| Base URL | https://api.deepseek.com |
| Model Name | deepseek-v4-pro 或 deepseek-v4-flash |
| Context Size | 1000000 |
| Max Tokens | 384000 |
保存后,所有 Dify 应用(聊天助手、Workflow、Agent)都能用 V4 了。Dify 部署教程参考。
2、Open WebUI 接入 V4
进入管理后台 → “Settings” → “Connections” → “OpenAI API”:
- API Base URL:
https://api.deepseek.com - API Key:你的 sk-xxx
保存后回到聊天界面,模型下拉框就能看到 deepseek-v4-flash 和 deepseek-v4-pro 了。
3、n8n 接入
n8n 的 OpenAI 节点也可以用:在节点配置里把 base_url 改成 https://api.deepseek.com,model 填 deepseek-v4-flash 即可。
4、Continue.dev(VSCode 插件)接入
{
"models": [
{
"title": "DeepSeek V4 Pro",
"provider": "openai",
"model": "deepseek-v4-pro",
"apiKey": "你的key",
"apiBase": "https://api.deepseek.com"
}
]
}
八、从 deepseek-chat 迁移到 V4
旧版 deepseek-chat 和 deepseek-reasoner 在 2026 年 7 月 24 日 15:59 UTC 彻底下线。如果你的应用还在用旧模型,现在就该迁移。
1、模型 ID 对照
| 旧模型 | 推荐替换 | 备注 |
|---|---|---|
| deepseek-chat | deepseek-v4-flash | 日常对话直接替换 |
| deepseek-chat | deepseek-v4-pro | 需要更高质量回复时用 |
| deepseek-reasoner | deepseek-v4-pro + thinking | 推理任务必须开 thinking |
2、迁移步骤
- 代码里搜索
deepseek-chat和deepseek-reasoner,替换成 V4 模型 - base_url 不需要改,仍然是
https://api.deepseek.com - API Key 不需要换,旧 Key 可以直接调 V4
- 推理任务原本用
deepseek-reasoner的,现在改成deepseek-v4-pro+thinking: {"type": "enabled"} - 测试通过后部署上线
3、Dify / Open WebUI 迁移
直接在模型配置里改 model name 即可,其他配置不变。改完保存重启服务。
九、DeepSeek V4 常见问题
1、长上下文调用失败
虽然 V4 默认 1M 上下文,但要确保:
- 输入 + 输出 token 总数不超过 1M
- 单次输出不超过 384K
- 客户端的 timeout 设置足够长(长上下文响应可能 30-60 秒)
OpenAI SDK 的 timeout 设置:
client = OpenAI(
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com",
timeout=120.0, # 单位:秒
)
2、搬瓦工 VPS 调 API 速度慢
可能原因:
- VPS 机房离 DeepSeek 服务器太远 → 切到 CN2 GIA-E 机房,访问国内服务最快
- 没用流式输出(stream=true)→ 长回复改流式,体感快很多
- thinking 模式开了不必要的开 → 简单任务关掉 thinking
3、想本地跑 V4 开源权重
V4-Pro 和 V4-Flash 权重都在 Hugging Face 上:
- https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash
但 Pro 需要顶级 GPU 集群(多张 H100/H200),Flash 也需要至少 4-8 张高端卡,搬瓦工 VPS 跑不动本地推理。直接调官方 API 是最现实的方案。
十、搬瓦工推荐套餐和新手教程
搬瓦工实时库存:https://stock.bwg.net
| 方案 | 内存 | CPU | 硬盘 | 流量/月 | 带宽 | 推荐机房 | 价格 | 购买 |
|---|---|---|---|---|---|---|---|---|
| KVM (最便宜) | 1GB | 2核 | 20GB | 1TB | 1Gbps | DC2 AO DC8 ZNET | $49.99/年 | 购买 |
| KVM | 2GB | 3核 | 40GB | 2TB | 1Gbps | $52.99/半年 $99.99/年 | 购买 | |
| CN2 GIA-E (最推荐) | 1GB | 2核 | 20GB | 1TB | 2.5Gbps | 美国 DC6 CN2 GIA-E 美国 DC9 CN2 GIA 日本软银 JPOS_1 荷兰 EUNL_9 美国圣何塞 CN2 GIA 加拿大 CN2 GIA | $49.99/季度 $169.99/年 | 购买 |
| CN2 GIA-E (AI 部署) | 2GB | 3核 | 40GB | 2TB | 2.5Gbps | $89.99/季度 $299.99/年 | 购买 | |
| SLA (SLA 保障) | 1GB | 独享2核 | 20GB | 1TB | 2.5Gbps | 美国 DC5 SLA 99.99% 在线率保证 每两周免费换 IP 一次 | $65.89/季度 $239.99/年 | 购买 |
| SLA (外贸建站) | 2GB | 独享3核 | 40GB | 2TB | 2.5Gbps | $116.99/季度 $399.99/年 | 购买 | |
| HK (高端首选) | 2GB | 2核 | 40GB | 0.5TB | 1Gbps | 中国香港 CN2 GIA 日本东京 CN2 GIA 日本大阪 CN2 GIA 新加坡 CN2 GIA | $89.99/月 $899.99/年 | 购买 |
| HK (高端建站) | 4GB | 4核 | 80GB | 1TB | 1Gbps | $155.99/月 $1559.99/年 | 购买 | |
| OSAKA (高端性价比) | 2GB | 2核 | 40GB | 0.5TB | 1.5Gbps | 日本大阪 CN2 GIA | $49.99/月 $499.99/年 | 购买 |
| OSAKA | 4GB | 4核 | 80GB | 1TB | 1.5Gbps | $86.99/月 $869.99/年 | 购买 | |
| 搬瓦工优惠码:暂无 | 搬瓦工购买教程:《2026 年最新搬瓦工购买教程和支付宝支付教程》 | |||||||
| 最新补货通知:点击查看 | 2026 搬瓦工补货通知群:200475672 | 280724862 | 852461608 | |||||||
选择建议:
- 入门:KVM 套餐,目前最便宜,可选 CN2 GT 机房,入门之选。
- 推荐:CN2 GIA-E 套餐,速度超快,可选机房多(DC6、DC9、日本软银、荷兰联通等),性价比最高。
- 高端:香港 CN2 GIA 套餐,价格较高,但是无可挑剔。大阪 CN2 GIA 套餐也是非常不错的高端选择。
搬瓦工新手教程
- 搬瓦工新手入门:《搬瓦工新手入门完全指南:方案推荐、机房选择、优惠码和购买教程》(推荐阅读)
- 搬瓦工购买教程:《2026 年最新搬瓦工购买教程和支付宝支付教程》
- 搬瓦工补货通知:《欢迎订阅搬瓦工补货通知(补货提醒)/ 加入搬瓦工交流群》
- 搬瓦工方案推荐:《搬瓦工高性价比 VPS 推荐:目前哪款方案最值得买?》
搬瓦工补货通知
| 渠道 | 名称 | ID / 群号 | 说明 |
|---|---|---|---|
| QQ 群(禁言) | 搬瓦工补货通知群 5 | 200475672 | 全员禁言,仅发送通知 |
| QQ 群(禁言) | 搬瓦工补货通知群 11 | 280724862 | 全员禁言,仅发送通知 |
| QQ 群(禁言) | 搬瓦工补货通知群 12 | 852461608 | 全员禁言,仅发送通知 |
| TG 频道 | 搬瓦工补货通知 TG 频道 | @BandwagonHostNews | 补货推送频道 |
| 微信 | 微信公众号 | 搬砖部落 | 补货会发推送 |
| 微信 | 微信号 | bwgvps | 补货通知会发在朋友圈 |
| 邮件订阅 | 搬瓦工补货邮件推送 | buhuo.bwg.net | 提交邮箱即可 |
| 实时库存 | 搬瓦工实时库存网站 | stock.bwg.net | 实时刷新库存状态 |
| 补货通知 | 《欢迎订阅搬瓦工补货通知(补货提醒)/ 加入搬瓦工交流群》 | ||

未经允许不得转载:Bandwagonhost中文网 » 2026 搬瓦工 VPS 调用 DeepSeek V4 API 教程:Pro / Flash 双模型 + 1M 上下文
